SD webui forge classicがsageattension 3に対応したので試してみた
sageattension 3
以前より高速化技術であるsageattension2に対応していたsd web ui forge classic(neo)がついにVer3に対応しました!
comfy uiでは以前より対応していたようですが、fork版とはいえsd webuiも対応した形になります。
このsageattension3(以下sage3)はRTX50シリーズで動作するパッケージであり、それ以前のシリーズでは機能しないとされています。
今回は実際にこのsage3を使ってどれほど効果があるか試してみようと思います。
比較
sage2
- windows 11
- RTX 5060 ti
- i7 8700K
- SD webui forge classic(neo) (commit: 7243041)
- 使用モデル anima preview3 base
まずは以前より使えるsage2のパッケージで生成を行います。
引数は以下
–sage –sage-function fp8_cuda++ –fast-fp16 –onnxruntime-gpu –pin-shared-memory –cuda-malloc –cuda-stream
環境はpython 3.13、torch 2.11、cuda 13.0
生成時の設定は以下

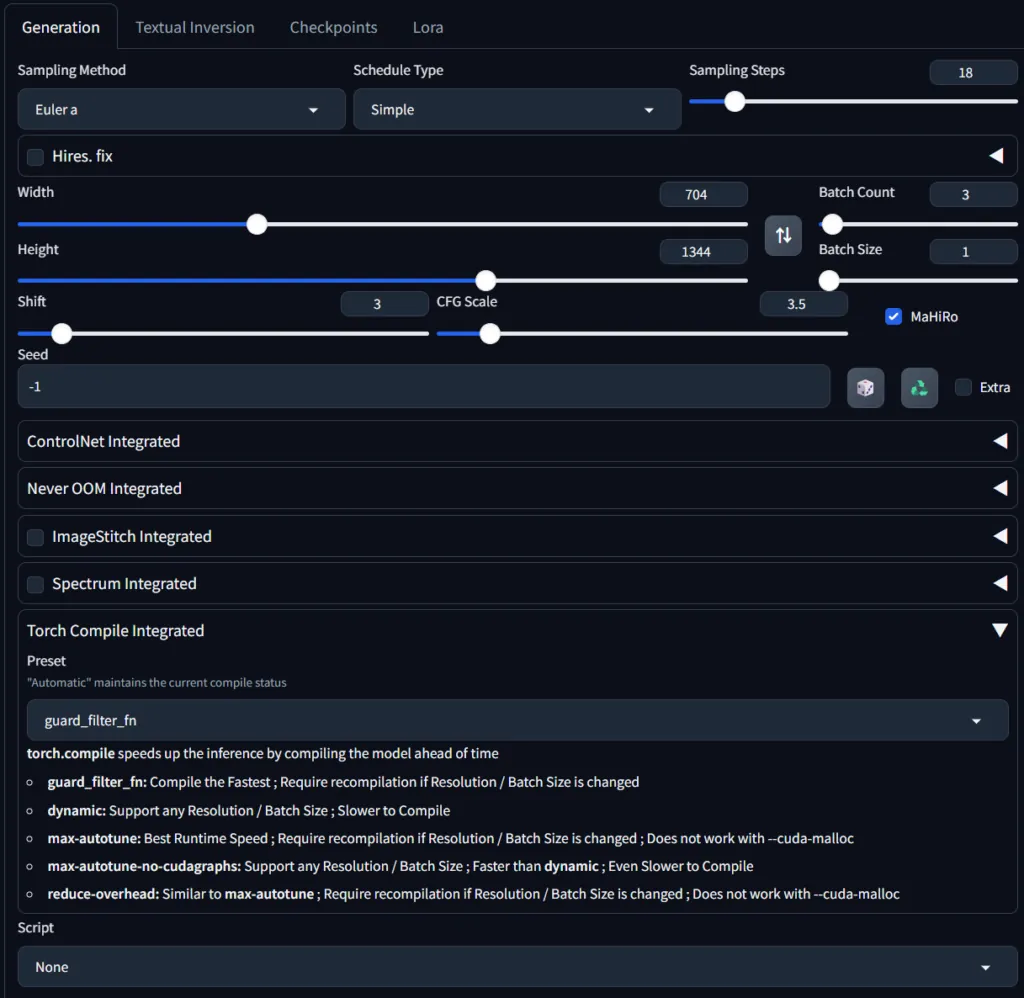
生成結果はこちら

Loraは2つ適応、初回のコンパイルを終わらせた状態、バッチ数3でかかった時間は28秒。
アップスケールせずに細部も潰れておらず、低ステップながら十分な品質を確保できています、sage2のモードはsage3対応とともに実装されたfp8_cuda++というモードだが、品質の劣化を感じさせない。
次に本命のsage3を試してみます。
sage3
まず環境をインストールするsage3に合わせて変更する必要があります、ここからsage3のホイールをダウンロードできます。

今回はvenvをuvで新規作成、python 3.13、torch2.9.1、cuda 13.0でテストします。
引数は以下
–sage –sage-function sageattn3 –fast-fp16 –onnxruntime-gpu –pin-shared-memory –cuda-malloc –cuda-stream

ちゃんとsage3が認識されていますね。
生成時の設定は先ほどと同じ条件で生成します。
一度同じシードで生成しましたがやはり結果が全然違ったので別シードでサンプル4枚。




1,2枚目はsage2でも見ない違和感が発生、ノッポになってしまっている。
3枚目は髪のリボンやスカートが破綻気味、4枚目は数回の生成で最も安定したものをチョイス。
また生成速度はsage2より早い27秒を記録、約1秒の高速化だと思っていい。
ただし、sage2のときはtorch 2.11でsage3はtorch 2.9.1とダウングレードしているので、sage3がtorch2.11で実行できれば更に早くなる可能性がある。
感想
正直sage3はまだ対応したばかりというのもあるのか、目に見えて品質に劣化を感じるものがあった。
ただし劣化しても手の破綻が少ないのは流石。
実際に新しい仮想環境を生成し試してみるのもいいかもしれません、ただしRTX50シリーズという条件がすこし敷居が高いかもしれません。
速度に関してはあまり上がらなかったなと言う感じ、正直事前コンパイルや他の最適化が仕事しすぎている感じもする。
品質を犠牲にこの速度であればまだsage2を使用し続けるほうがいい気がしたのでvenvの指定と引数を前の環境に戻した。
ちなみにloraをfp16で使うモードも試したが生成時間が1.5倍伸びたので通常の使用で問題ない。
xformersもvaeにだけ機能するというので使っていたが、正直使っても使ってなくても速度にも品質にも影響があまりなかった。
使用メモリの削減には貢献してたかもしれない。
今回の検証では外している、でももう使わないかも。